

Managing tasks efficiently is essential in our daily lives, and with the power of modern APIs and libraries, we can streamline this process.
In this article, we’ll walk through creating a Python-based application that integrates the Todoist API with Speech-to-Text (STT), Text-to-Speech (TTS), and a Text User Interface (TUI) using the Textual library.
This application enables you to manage tasks hands-free and interactively, all while working offline using CPU.
Full source code zip file available to download at the end of the article.
Key Features
The key features of this application are as follows:
- Integration with Todoist API: The Todoist API allows us to interact with our task list programmatically. This means you can fetch tasks, add new tasks, or delete tasks directly from the application without needing to open the Todoist app.
- Speech-to-Text (STT): Using advanced models, this feature enables users to create tasks by speaking, making it especially useful for hands-free task management.
- Text-to-Speech (TTS): This feature lets the app read out tasks to you, providing an auditory way to review tasks.
- Text User Interface (TUI): The Textual library provides a clean and interactive text-based interface to manage tasks visually without needing a graphical environment.
Libraries and Tools Used
faster-whisper
The faster-whisper library is a highly optimized implementation of the Whisper model for Speech-to-Text.
It supports multiple model sizes and is designed for fast, accurate transcription while being resource-efficient.
Its features include:
- Model Size Options: Choose from small, medium, or large models depending on your hardware capabilities.
- INT8 Quantization: Reduces memory usage and computation time, ideal for running on CPUs.
- Offline Functionality: Operates entirely offline, ensuring privacy and independence from external servers. A network connection is necessary to initially download the selected model.
pyttsx3
pyttsx3 is a Text-to-Speech conversion library that works offline and supports multiple speech engines.
Its key features include:
- Cross-Platform: Compatible with Windows, macOS, and Linux.
- Customizable Voices: Allows selection of different voices, adjusting speech rate, and volume.
- Offline Functionality: Does not require an internet connection, making it ideal for standalone applications.
sounddevice and scipy
These libraries work together to handle audio recording and processing:
- sounddevice: Provides a simple interface for recording and playing audio in real-time. It supports multiple audio backends.
- scipy: Includes tools to process recorded audio, such as saving it in WAV format.
todoist-api-python
This is the official Python wrapper for the Todoist REST API, enabling seamless integration with Todoist.
Its features include:
- Task Management: Create, read, update, and delete tasks.
- Project Integration: Work with specific Todoist projects using their IDs.
- Error Handling: Built-in mechanisms to manage API rate limits and exceptions.
Textual
Textual is a modern Python library for creating rich, interactive Text User Interfaces (TUIs).
Its features include:
- Widget-Based Design: Simplifies building complex interfaces using widgets like buttons, tables, and scrollable areas.
- Asynchronous Framework: Ensures smooth performance with non-blocking UI updates.
- Styling with CSS: Customize the appearance of your TUI using CSS-like syntax.
Setting Up the Environment
Before diving into the code, ensure you have the necessary dependencies installed.
Use the following command:
pip install faster-whisper pyttsx3 todoist-api-python sounddevice scipy textual python-decouple
Additionally, create a .env file to securely store your Todoist API credentials:
TODOIST_API_KEY=your_todoist_api_key
TODOIST_PROJECT_ID=your_project_id
Replace your_todoist_api_key and your_project_id with your actual Todoist API key and project ID.
Why You Need a Todoist API Key
The Todoist API key is essential for authenticating your application to interact with your Todoist account.
It ensures that the app can securely fetch, create, and delete tasks in your specific projects.
Without the API key, the application cannot communicate with Todoist.
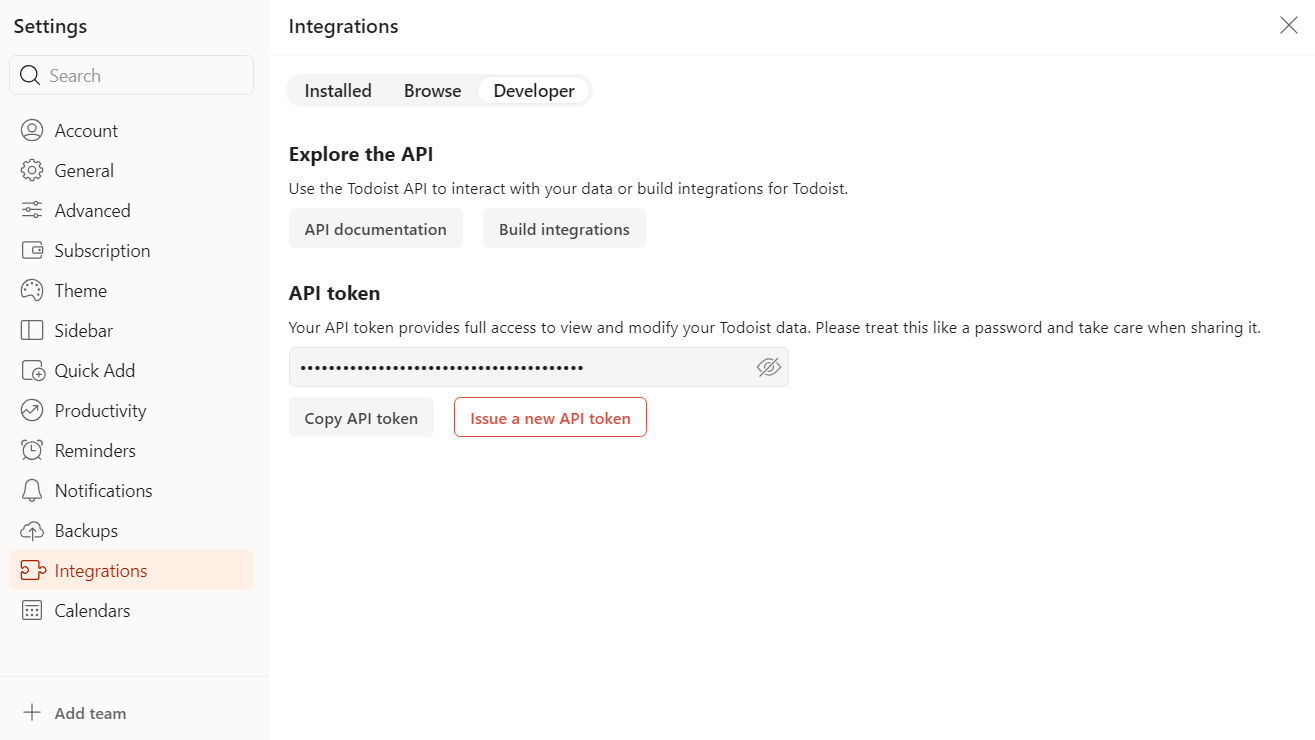
To obtain your key, visit your Todoist Settings and generate a personal API token under Developer Integrations:
Code Breakdown
Let's now begin to write the code for our application.
We will first start with the wrappers for the different libraries and then build the main application with the Textual library.
Speech-to-Text (STT)
Speech-to-Text functionality is implemented using the faster-whisper library.
This library provides fast and accurate transcription of audio files.
Here’s how it works, file is transcribe_wrapper.py:
# transcribe_wrapper.py
from faster_whisper import WhisperModel
# Run on CPU with INT8 quantization
model_size = "medium.en"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
# Transcribe an audio file
def transcribe(audio_path):
segments, _ = model.transcribe(audio_path)
# Return the words
text = ""
for segment in segments:
text += segment.text
return text
The transcribe_wrapper.py script transcribes audio files into text using the faster_whisper library:
- The script imports the
WhisperModelclass fromfaster_whisper. - It initializes a medium-sized English language model (
"medium.en"). - The model is configured to run on the CPU with INT8 quantization for improved performance and reduced model size.
- The
transcribefunction takes an audio file path as input. - It uses the
transcribemethod of theWhisperModelto process the audio file. - The method returns segments of transcribed text.
- The function concatenates these segments into a single string.
- The concatenated text is returned as the output.
Text-to-Speech (TTS)
The Text-to-Speech functionality is handled by the pyttsx3 library, which converts text into speech.
This feature makes the app accessible and interactive. Let's see the file text_speech_wrapper.py:
# text_speech_wrapper.py
import pyttsx3
# Initialize the text-to-speech engine
engine = pyttsx3.init()
# Convert text to speech
def convert_text_to_speech(text):
engine.say(text)
engine.runAndWait()
The script provides a straightforward way to initialize the TTS engine and convert text into audible speech:
- The script initializes the TTS engine using the
pyttsx3.init()function. - It defines a function called
convert_text_to_speechthat takes a string of text as input. - Inside the function, the
engine.say(text)method queues the text for speech synthesis. - The
engine.runAndWait()method processes the queued commands and plays the synthesized speech.
Audio Recording
Recording audio is made possible with the sounddevice and scipy libraries.
The recorded audio is saved as a WAV file. Let's see the file recording_wrapper.py:
This article is for paid members only
To continue reading this article, upgrade your account to get full access.
Subscribe NowAlready have an account? Sign In