This article is for paid members only
To continue reading this article, upgrade your account to get full access.
Subscribe NowAlready have an account? Sign In

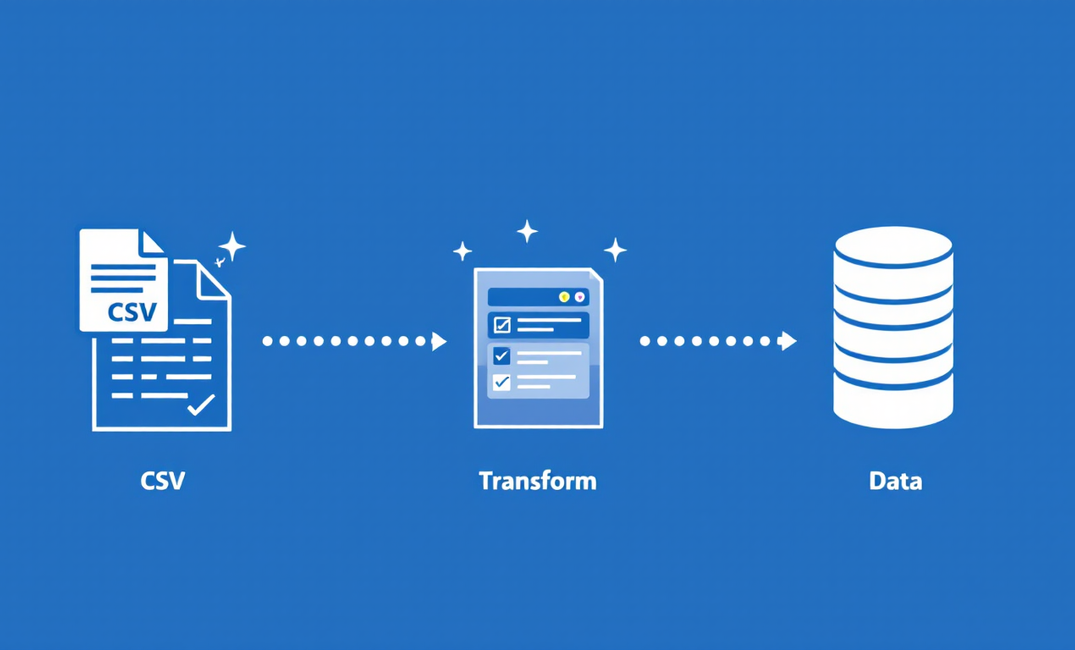
Using Pydantic for ETL - Clean, Validate, and Transform Data with Confidence
To continue reading this article, upgrade your account to get full access.
Subscribe NowAlready have an account? Sign In