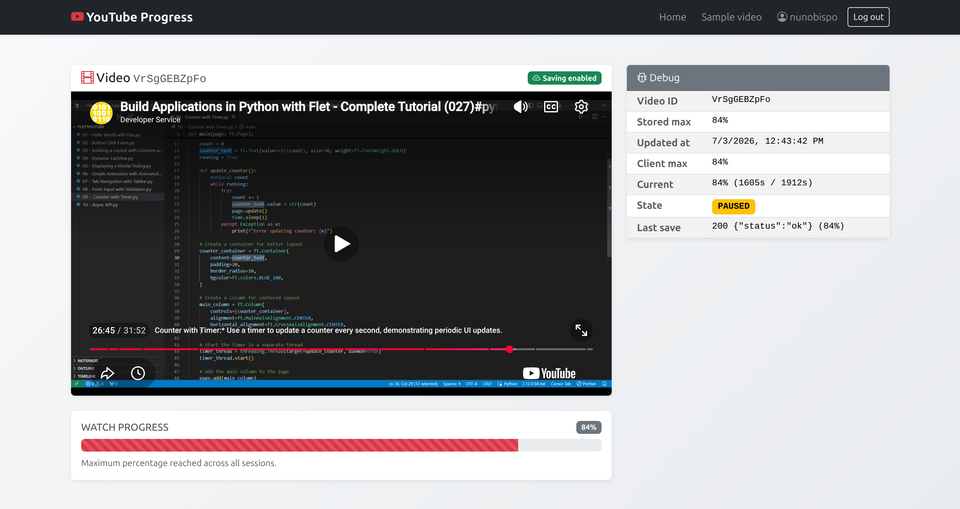
Your Django app serves a YouTube video. The page loads, the player appears, and your database records nothing. You have no idea whether the user pressed play, watched ten seconds, or finished the whole thing.
When you're choosing an agent framework, popularity is the wrong scorecard. Pick the one that fails loudly in development and gracefully in production - or you'll find out in audit.
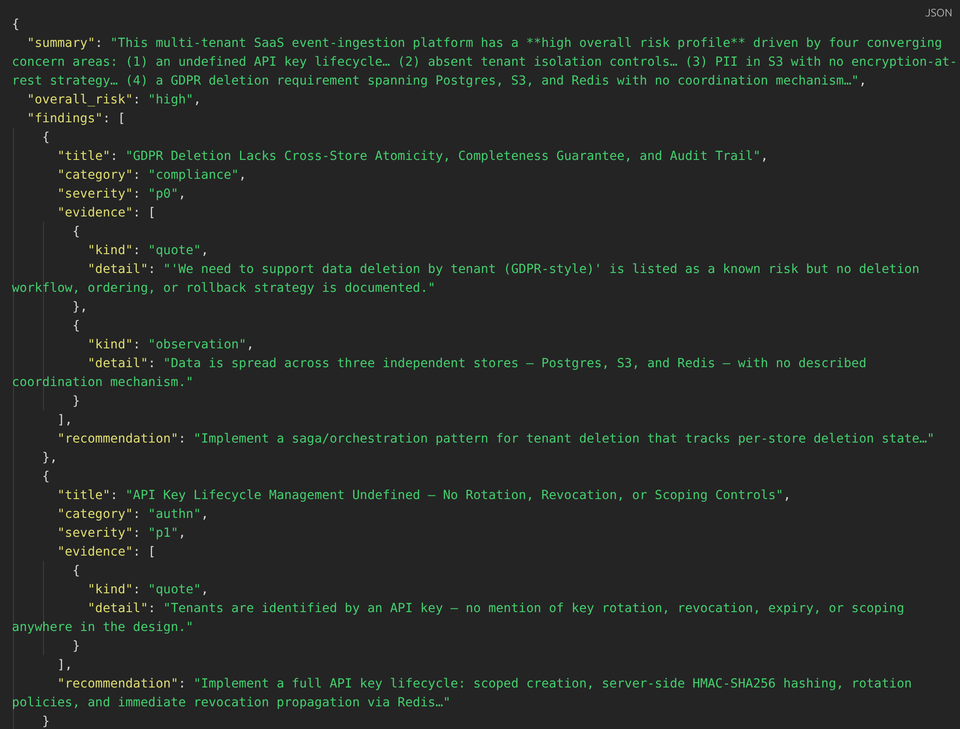
This article shows how to build a multi-agent architecture reviewer that produces a structured review artifact: normalized findings with severity, evidence, and recommendations, plus clarifying questions and explicit “needs human judgment” flags.
Python dependency management is not a developer problem. It is a team productivity problem that shows up as slow CI, painful on-boarding, and a different tool in every repository.
This article is for the ones building an LLM product and want to know what it actually costs you - per feature, per user, per request - without paying for Datadog or wiring up OpenTelemetry.