

LLMs aren’t struggling with intelligence, they’re suffocating under too many useless tokens. Even a million-token context window can choke on long documents and multi-step agent chains.
But here’s the twist: most of those tokens are predictable grammar the model doesn’t even need.
Telegraphic Semantic Compression (TSC) cuts out the linguistic fluff and keeps only the high-value facts; names, numbers, entities, relationships. The stuff LLMs can’t reconstruct on their own.
In this article, you’ll see how TSC works, how it slashes context size without losing meaning, and how to implement it in Python.
What Is Telegraphic Semantic Compression (TSC)?
Telegraphic Semantic Compression (TSC) is a lossy semantic compression technique that removes predictable grammatical structure while preserving the high-entropy, fact-rich details that actually carry meaning.
Unlike traditional summarization, which often omits or rephrases important information, TSC retains all meaningful data points. It simply expresses them in a compact, telegraphic style, similar to classic “telegram language.”
Before → After Example
Original:
“The Eiffel Tower, located in Paris, France, was built in 1889 for the Exposition Universelle.”
TSC Output:
Eiffel Tower. Paris France. Built 1889. Exposition Universelle.
The core meaning remains fully intact. Only the predictable grammar is removed.
Visual Overview: The TSC Pipeline
To understand Telegraphic Semantic Compression (TSC) at a glance, here’s a step-by-step breakdown of how raw text is transformed into compact, fact-dense telegraphic form.
The diagram illustrates how predictable grammar is stripped away while high-entropy, meaning-bearing tokens are preserved and recombined into concise semantic fragments.
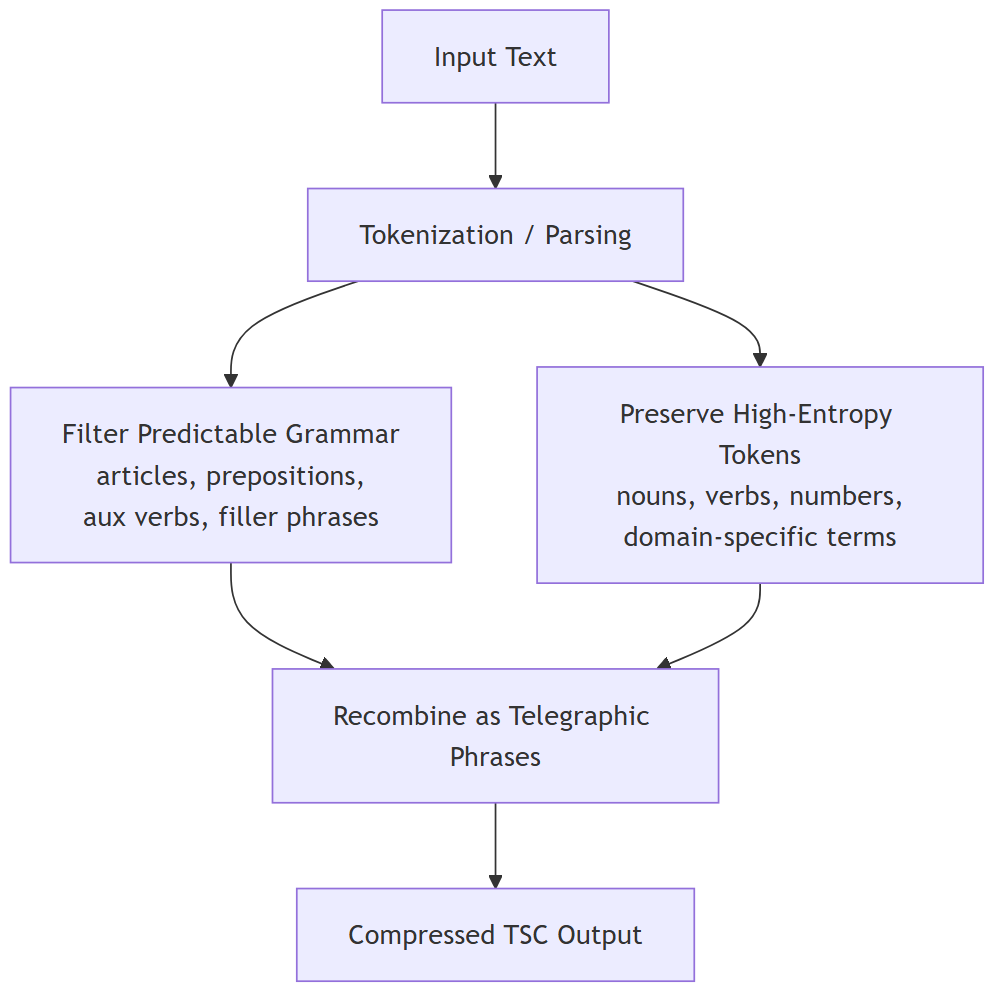
How to Read the Diagram
- Input Text → Tokenization: The text is broken into tokens; words, punctuation marks, and linguistic units.
- Filtering Predictable Grammar: Articles (“the”, “a”), prepositions (“of”, “in”), auxiliary verbs (“was”, “is”), and other low-information tokens are removed. These convey structure, not meaning.
- Preserving High-Entropy Tokens: Important words; nouns, verbs, numbers, entity names, and domain-specific vocabulary; are preserved. These contain the unpredictable, fact-rich information an LLM cannot guess.
- Recombining into Telegraphic Phrases: The retained tokens are assembled into short, dense fragments that resemble classic telegram language. The phrasing is minimal, but the semantics remain intact.
- Output: Compressed TSC Text: The final result is dramatically shorter yet semantically rich, ideal for long-context LLM pipelines and multi-step reasoning workflows.
Why Telegraphic Semantic Compression Works So Well for LLMs
Large Language Models excel at predicting and reconstructing natural language. After training on trillions of sentences; grammar, syntax, and common phrasing are almost trivial for them to generate. In practice, LLMs do not need reminders about how English works, they can effortlessly restore the connective tissue of a sentence.
What LLMs can’t easily infer, however, is the unpredictable, fact-dense content that carries a text’s actual meaning.
These are the details that must be preserved explicitly:
- Dates: Years, timestamps, eras, historical markers.
- Names: People, cities, organizations, products.
- Rare or domain-specific terms: Specialized vocabulary or low-frequency words.
- Technical language: Jargon, formulas, measurements, scientific terms.
- Numerical relationships: Counts, ratios, quantities, comparative values.
- Niche domain facts: Information unlikely to appear in generic training data.
Telegraphic Semantic Compression (TSC) exploits this asymmetry. It removes what an LLM can reliably predict; grammar, filler words, and structural glue; while preserving the information it cannot reconstruct from context.
The result is that more of your context window is spent on meaningful, high-entropy information, instead of predictable linguistic scaffolding.
By leaning on the model’s natural talent for regenerating fluent English, TSC produces dramatically denser and more efficient prompts without sacrificing the factual integrity of the original text.
If you’re interested in simplifying your AI/NLP workflows even further, check out my article “Replace Expensive AI with Free TextBlob: Stop Paying for Simple NLP Tasks”. It’s packed with examples, comparisons, and practical tips for getting started.
Python Implementation: Compress and Measure Token Savings
Below is a minimal-but-functional Telegraphic Semantic Compression (TSC) pipeline built with spaCy.
We’ll also measure token counts before and after compression using tiktoken to quantify how much context you save when using TSC inside LLM prompts.
This makes it easy to evaluate efficiency gains in real workflows.
Install Prerequisites
pip install spacy tiktoken
python -m spacy download en_core_web_sm
This installs the required dependencies by adding spaCy and tiktoken, then download the English language model for spaCy.
Basic TSC Compressor
This article is for paid members only
To continue reading this article, upgrade your account to get full access.
Subscribe NowAlready have an account? Sign In