Why Architecture Reviews Need Contracts, Not Chat
Architecture reviews have a translation problem.
Humans can leave a thread of “consider X” and “what about Y” and resolve the rest in a meeting. But if you want an LLM to participate in a workflow that resembles engineering - PRs, ADRs, ticketing, CI gates - fluent feedback isn’t enough. You need output that downstream systems (and humans) can reliably act on.
Most “LLM architecture review” demos stop at persuasive prose. The result reads like an experienced engineer, but it isn’t shaped like an artifact: it’s hard to rank, route, deduplicate, or turn into work without a second manual pass.
Multi-agent helps because architecture review is a bundle of lenses - security, scalability, operability, cost, data integrity, failure recovery - each with its own heuristics and thresholds. But the real differentiator isn’t “one agent vs. many”. It’s contracts. With PydanticAI, you define the schema the system must emit and validate every response; Claude supplies the reasoning, but the contract forces it into a machine-actionable shape.
This article shows how to build a multi-agent architecture reviewer that produces a structured review artifact: normalized findings with severity, evidence, and recommendations, plus clarifying questions and explicit “needs human judgment” flags. Think less chatbot, more review report.
The full runnable example lives in the companion repository:
In the next sections, we’ll define the minimal topology (planner → specialists → synthesizer), the shared contracts, and an end-to-end walkthrough from design doc to structured report.
What Multi-Agent Buys You (and What It Costs)
Multi-agent systems are easy to overuse. If all you need is a single round of feedback - “scan this design doc for obvious risks” or “suggest alternatives for this storage layer” - a well-constructed prompt with a structured output schema can get you most of the value with a fraction of the complexity. The moment you add agents, you add orchestration, state, and failure handling; if you don’t get clear returns, you’ve just built a slower, more expensive version of a single call.
So what does multi-agent actually buy you for architecture review? Primarily: separation of concerns and parallel perspectives. A single “review this architecture” prompt tends to collapse into a handful of generic patterns: it repeats the same risks across categories, it misses domain-specific edge cases, and it blurs “ask a question” with “assert a fact”. Splitting the work into roles lets you put sharper instructions and narrower context windows in front of each agent, and it gives you a natural place to express uncertainty (“as the security reviewer, I need X to conclude Y”).
Monolithic prompts also fail in predictable ways. They produce long outputs that are hard to rank; they mix high-confidence issues with speculative ones; they contradict themselves; and they often lack traceable evidence tied to the input. Those failures aren’t just aesthetic - they make downstream automation unreliable. If you can’t consistently tell what is a “P0” vs. a “P3”, or what is a requirement vs. a suggestion, you can’t turn the review into an engineering workflow.
The costs are real. Fan-out (running multiple specialists) increases token spend and latency, and it introduces coordination overhead: you need to manage shared context, avoid duplication, and merge disagreements into a single report. Sequential pipelines can reduce duplication and keep context tighter, but they can amplify early mistakes (if the first step narrows scope incorrectly, everything downstream inherits that error). In practice, you’re trading a single model call for a small distributed system.
For a lean architecture reviewer, a minimal topology works well:
- A planner reads the input and decides which lenses to apply (security, scalability, operability, data, cost), plus any clarifying questions.
- A small set of specialists each run one lens and emit findings in a shared schema.
- A synthesizer merges the results: deduplicates, ranks, resolves contradictions (or preserves dissent explicitly), and produces the final structured review artifact.
The decision heuristic is simple: stay lean unless you need genuinely different perspectives. If your review output is consistently repetitive, shallow, or internally inconsistent, specialist roles can help. If you’re already getting high-quality structured output from one call, don’t add agents - add better contracts, better evidence requirements, and better “unknowns” handling.
Contracts First: Pydantic Models as the Agent API
If you only take one idea from this article, it should be this: the schema is the product. The model is a reasoning engine, but your system’s reliability comes from the contract you force that reasoning to satisfy. Most agent demos skip this and then wonder why their outputs can’t be trusted in an engineering workflow.
Architecture review is especially sensitive to this because it’s full of ambiguity. Some findings are hard requirements (“this violates a compliance constraint”), some are conditional (“if traffic can spike 10×, you need backpressure”), and some are simply questions (“what is your RTO/RPO?”). Without a contract that distinguishes these categories - and forces the model to attach evidence or explicitly mark unknowns - you end up with prose that sounds plausible but is operationally unusable.
In Pydantic terms, you want to model the output as a small set of types that match how engineers actually consume reviews. A typical core might include:
- A top-level
ArchitectureReviewartifact (metadata, overall risk, summary). - A list of
Findingobjects with fields liketitle,severity,category, andrecommendation. - An
evidenceorreferencesfield that ties the claim to something in the input (or marks it as an inference). - A separate list of
questionsfor missing information that blocks a confident conclusion.
The exact fields are less important than the discipline: every claim must land somewhere explicit. Severity can’t be buried in adjectives. Recommendations can’t be scattered across paragraphs. Uncertainty can’t be implied; it needs a home in the schema.
Contracts also apply to inputs. Each agent role should have a clear definition of what context it is allowed to assume and what it must treat as unknown. That’s the difference between a specialist saying “use mTLS” by default versus saying “if there are multi-tenant boundaries or untrusted networks, consider mTLS; otherwise justify why it’s unnecessary”. The more explicit you are about inputs (constraints, traffic assumptions, data classification, SLOs), the less your agents have to guess.
Once you have contracts, you can make the system resilient with validation and repair loops. With PydanticAI-style structured outputs, you can:
- Validate every model response against the schema.
- Retry on validation failure with a targeted instruction (“output must include
evidencefor each finding”). - Apply a small “repair” step when the model is close but not quite compliant (missing a field, wrong enum value).
This isn’t about being pedantic. It’s what turns “LLM output” into “typed data” you can route downstream: create issues in a tracker, post a summarized comment to a PR, generate an ADR checklist, or feed a dashboard that tracks the recurring classes of architectural risk your org keeps rediscovering.
Multi-agent orchestration only works well when everyone speaks the same language. The contract is that language.
If you want to go deeper on modeling, validation, and the patterns that make Pydantic contracts reliable in production, see Practical Pydantic - a hands-on guide to data validation in Python, from core concepts through real-world APIs and pipelines.
Code example: a minimal contract set
The working example in models.py defines a small set of Pydantic models that act as the “agent API” for planning, specialist review, and synthesis:
from enum import Enum
from typing import Literal
from pydantic import BaseModel, Field
class Lens(str, Enum):
security = "security"
scalability = "scalability"
operability = "operability"
data_integrity = "data_integrity"
class Severity(str, Enum):
p0 = "p0"
p1 = "p1"
p2 = "p2"
p3 = "p3"
class Evidence(BaseModel):
kind: Literal["quote", "observation", "inference"] = "observation"
detail: str = Field(..., description="Quote or observation tied to the provided input.")
class Finding(BaseModel):
title: str
category: str = Field(..., description="Short category label (e.g. authz, backpressure).")
severity: Severity
evidence: list[Evidence] = Field(default_factory=list)
recommendation: str
class PlannerOutput(BaseModel):
lenses: list[Lens]
scope_notes: str = ""
clarifying_questions: list[str] = Field(default_factory=list)
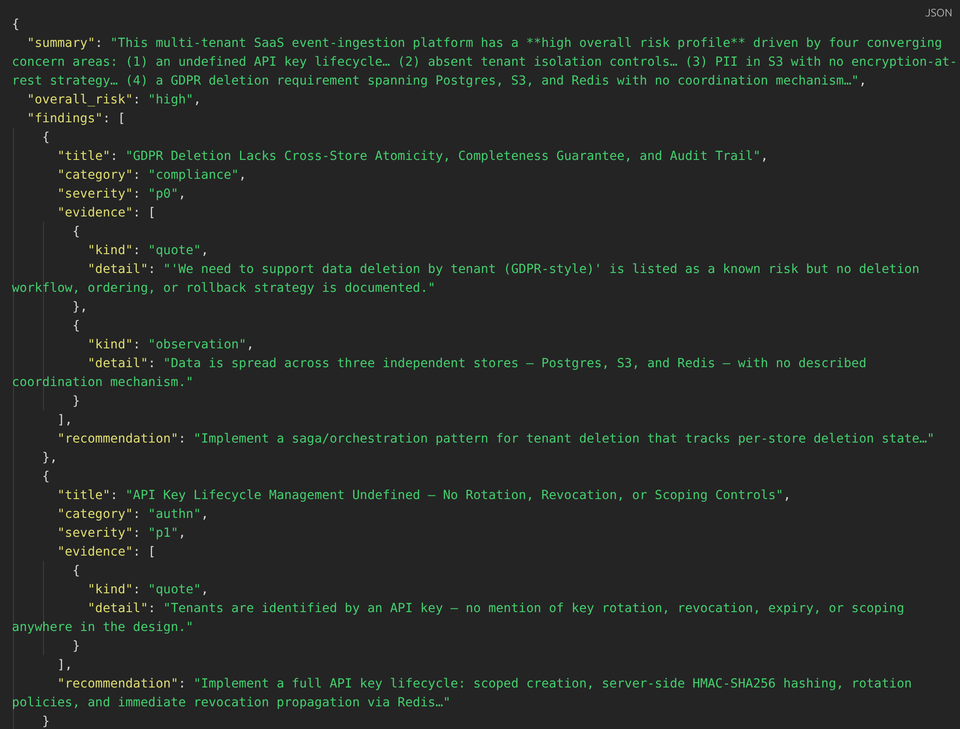
class ArchitectureReview(BaseModel):
summary: str
overall_risk: Literal["low", "medium", "high"] = "medium"
findings: list[Finding] = Field(default_factory=list)
questions: list[str] = Field(default_factory=list)
Role Design: Planner, Specialists, Synthesizer
The fastest way to ruin a multi-agent system is to give every agent the same vague job: “review the architecture”. You’ll pay for multiple calls and still get duplicated, generic output. Role design is where multi-agent becomes an engineering tool instead of a prompt trick.
A useful rule is: each role must have a one-sentence job description that is both necessary and non-overlapping. If two roles can produce the same kind of output, you haven’t created separation of concerns - you’ve created redundancy.
For a lean architecture reviewer, three roles are enough:
Planner
The planner’s job is to decide what review should happen given the input and constraints. It does not emit a full review. It produces:
- Which lenses to apply (security, scalability, operability, cost, data integrity, compliance, etc.).
- Any clarifying questions that block a confident review (“What’s the expected peak RPS?”, “What is the data classification?”).
- Optional scoping notes (“Focus on failure recovery and multi-region; ignore UI concerns.”).
This role is where you avoid wasted work. If the architecture is a batch pipeline with no public ingress, a deep web security pass is noise. If it’s a multi-tenant SaaS, ignoring tenant boundaries is negligence. The planner sets those priorities explicitly.
Specialists
Each specialist’s job is to run one lens and emit findings in the shared contract. Specialists should not:
- Re-scope the review (“I think we should also do operability”).
- Invent missing context as if it were true.
- Produce long narrative prose that the synthesizer can’t merge.
They should be opinionated within their lens, but disciplined about uncertainty. A good specialist output contains high-signal findings and clear questions when key context is missing. The contract is the forcing function: each finding needs a category, a severity, evidence, and a recommendation.
Synthesizer
The synthesizer’s job is to produce the final ArchitectureReview artifact. That means:
- Deduplicate overlapping findings across specialists.
- Resolve contradictions when possible, or preserve dissent when it matters (“Security flags P0 unless X; Scalability says acceptable if Y”).
- Rank and prioritize based on severity and expected impact.
- Produce a concise summary that is consistent with the structured findings, not an independent “new” review.
The synthesizer is also where you enforce global policy: severity definitions, house style, and what counts as acceptable evidence. In other words, it turns a bag of lens-specific opinions into a single report that an engineering team can act on.
Prompt boundaries
Prompt boundaries are not decorative; they prevent scope creep and hallucinated authority. Each role should have explicit “must not” constraints. Examples:
- The planner must not emit findings.
- Specialists must not rewrite the contract or invent missing facts.
- The synthesizer must not add new findings that were not supported by specialist outputs or input evidence (unless explicitly marked as an inference with low confidence).
When roles are crisp, orchestration becomes straightforward: you know what inputs each step needs and what outputs it is allowed to produce. When roles are fuzzy, you’ll spend your time chasing inconsistencies and blame-shifting between agents.
Code example: defining role agents
In the working example (reviewer.py), each role is an Agent with an output_type set to one of the contracts, and all roles share the same dependency type (ReviewDeps) carrying the design doc.
Passing deps=ReviewDeps(design_doc=...) alone is not enough: PydanticAI does not automatically inject dependencies into the prompt. Use dynamic instructions to attach the document to every run:
from __future__ import annotations
import os
from dotenv import load_dotenv
from dataclasses import dataclass
from pydantic_ai import Agent, RunContext
from models import ArchitectureReview, Lens, PlannerOutput, SpecialistOutput
load_dotenv()
DEFAULT_MODEL = os.getenv("MODEL", "anthropic:claude-sonnet-4-6")
if not os.getenv("ANTHROPIC_API_KEY"):
raise RuntimeError(
"ANTHROPIC_API_KEY is not set. Export it or add it to a .env file in the project root."
)
@dataclass(frozen=True)
class ReviewDeps:
design_doc: str
planner = Agent(
DEFAULT_MODEL,
deps_type=ReviewDeps,
output_type=PlannerOutput,
instructions=(
"You are an architecture review planner. "
"Given the design doc, choose which review lenses to run, "
"write scoping notes, and list clarifying questions. "
"Prefer asking questions over guessing."
),
)
@planner.instructions
def planner_design_doc(ctx: RunContext[ReviewDeps]) -> str:
return f"Design doc to review:\n\n{ctx.deps.design_doc}"
def make_specialist(lens: Lens) -> Agent[ReviewDeps, SpecialistOutput]:
specialist = Agent(
DEFAULT_MODEL,
deps_type=ReviewDeps,
output_type=SpecialistOutput,
instructions=(
f"You are the {lens.value} specialist for an architecture review.\n"
"Return findings using the output schema.\n"
"- Every finding should include concrete evidence tied to the input.\n"
"- If you lack evidence, ask a question instead of inventing facts.\n"
"- Be concise; prioritize the highest-impact issues."
),
)
@specialist.instructions
def specialist_design_doc(ctx: RunContext[ReviewDeps]) -> str:
return f"Design doc to review:\n\n{ctx.deps.design_doc}"
return specialist
synthesizer = Agent(
DEFAULT_MODEL,
deps_type=ReviewDeps,
output_type=ArchitectureReview,
instructions=(
"You are the synthesizer for a multi-agent architecture review.\n"
"Merge specialist outputs into one ArchitectureReview:\n"
"- Deduplicate overlapping findings.\n"
"- Rank by severity and impact.\n"
"- If specialists disagree, either resolve via evidence or preserve uncertainty.\n"
"- Keep the summary consistent with the structured findings."
),
)
@synthesizer.instructions
def synthesizer_design_doc(ctx: RunContext[ReviewDeps]) -> str:
return f"Design doc that was reviewed:\n\n{ctx.deps.design_doc}"
...
Routing Topology: Fan-Out, Sequence, and When to Stop
With roles defined, the next question is routing: in what order do you run them, what state do you pass, and when do you stop? “Agent frameworks” often treat routing as a generic problem (graphs, tool routers, memory stores). Architecture review is narrower. You want a topology that is predictable, auditable, and cheap enough to run often.
There are three common patterns that fit this use case:
Fan-out then synthesize (standard)
Planner → Specialists (parallel) → Synthesizer.
This is usually the sweet spot. The planner scopes and selects lenses, specialists run independently in parallel, and the synthesizer merges. Parallelism gives you speed and reduces the chance that one lens anchors another. The cost is duplication and conflict, which you then handle in synthesis.
Gated sequence (when context is expensive)
Planner → Specialist A → Specialist B → … → Synthesizer.
Sequential routing makes sense when later steps depend on structured state produced earlier (e.g., the planner extracts a component inventory; specialists review component-by-component). The risk is error propagation: a missed component early can cause systematic blind spots.
Two-pass loop (only when you need it)
Planner → Specialists → Synthesizer → (optional) targeted re-asks → Synthesizer.
If you do loops, keep them narrow. The goal isn’t “let the agents think longer”. It’s to repair specific defects: missing evidence, unclear severity, or unresolved contradictions. Targeted re-asks are cheaper and more reliable than open-ended “review again”.
State passing: structured, not conversational
The “chat history soup” failure mode is real: you pass the entire transcript to every agent and hope they find what they need. The result is inconsistent emphasis and increasing token waste. For architecture review, treat state as data:
- The raw input (design doc excerpt, constraints, assumptions).
- A structured planner output (selected lenses, clarifying questions, scope notes).
- A shared contract for specialist findings.
- The synthesizer’s merged artifact.
This keeps each step anchored to the same fields, and it makes runs auditable: you can see which agent produced which finding and why.
Stopping conditions
In a lean system, stopping conditions should be boring and strict. Common rules:
- Max rounds: no unbounded loops; if you need a third pass, you likely need a better contract or better inputs.
- Empty findings: if specialists return no issues, don’t “try harder” unless the planner flagged missing context.
- Low-confidence signals: if evidence is missing, prefer explicit questions/unknowns over additional speculative rounds.
Reference topology
The reference topology we’ll use in the end-to-end walkthrough is:
Planner → (Security, Scalability, Operability, Data/Integrity) specialists in parallel → Synthesizer.
If you add anything, add it reluctantly - and only after you can name the specific failure mode it fixes.
I review Python and AI codebases for security gaps, production readiness, and long-term maintainability. If that's something your team needs, let's talk.
Code example: orchestration (planner → specialists → synthesizer)
The same example wires the routing logic directly in Python, passing structured state (planner output, specialist JSON) rather than a growing chat transcript: