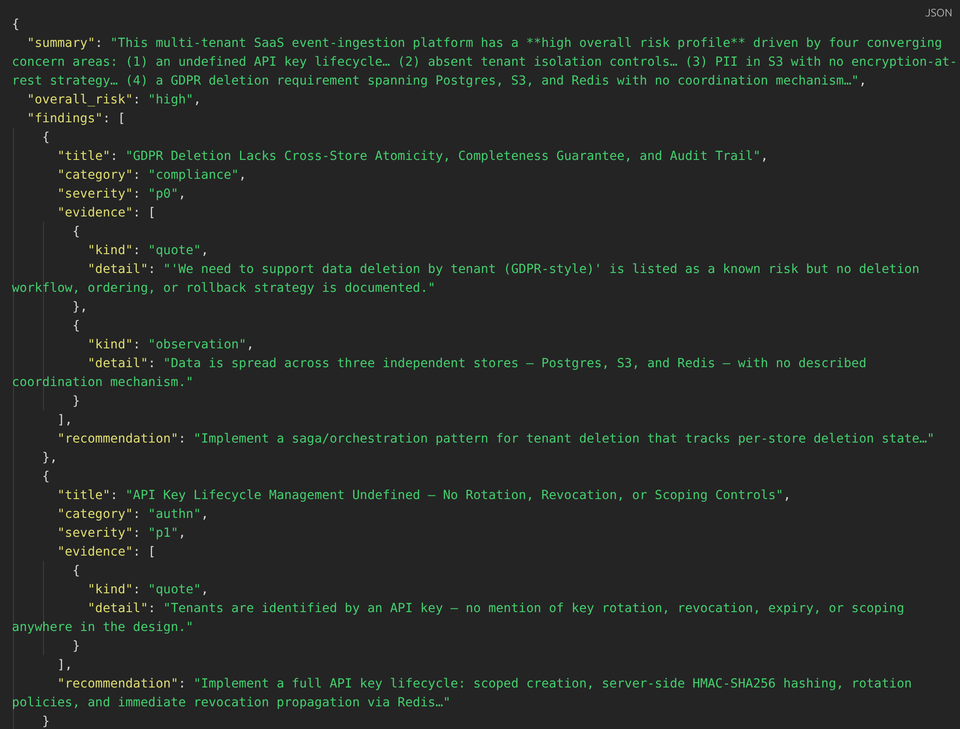
This article shows how to build a multi-agent architecture reviewer that produces a structured review artifact: normalized findings with severity, evidence, and recommendations, plus clarifying questions and explicit “needs human judgment” flags.
This article is for the ones building an LLM product and want to know what it actually costs you - per feature, per user, per request - without paying for Datadog or wiring up OpenTelemetry.
We will walk through a concrete RAG example - a pipeline over a corporate annual report - and build the testing layer that most teams skip entirely. The code is real and runnable. The failures are not hypothetical.